Understanding floating point numbers
introduction#
In 1991, a Patriot missile defense system in Saudi Arabia failed to intercept an incoming Scud missile, resulting in the tragic deaths of 28 American soldiers. The cause? A tiny floating point error that accumulated over time, throwing off the system’s timing by just 0.34 seconds. This incident highlights the critical importance of understanding floating point numbers in computer systems. Floating point representation allows computers to work with a wide range of real numbers, from the microscopic to the astronomical. However, it also introduces complexities and potential inaccuracies that programmers must carefully navigate.
It is important to understand the way we represent floating point numbers in computers to avoid unwanted edge cases in programming. if you are considering to use float32 for managing your finances just because you would be able to represent cents be mindful that IEEE 754 skips a number after 2^24 (16,777,217). At this point you are not only missing numbers but errors due to calculations keeps on adding up.
Disclaimer Throughout this writeup i will be consistently switching between hardware and its usecases in
writing applications as we are bound by the hardware design
how is floating point numbers represented in binary#
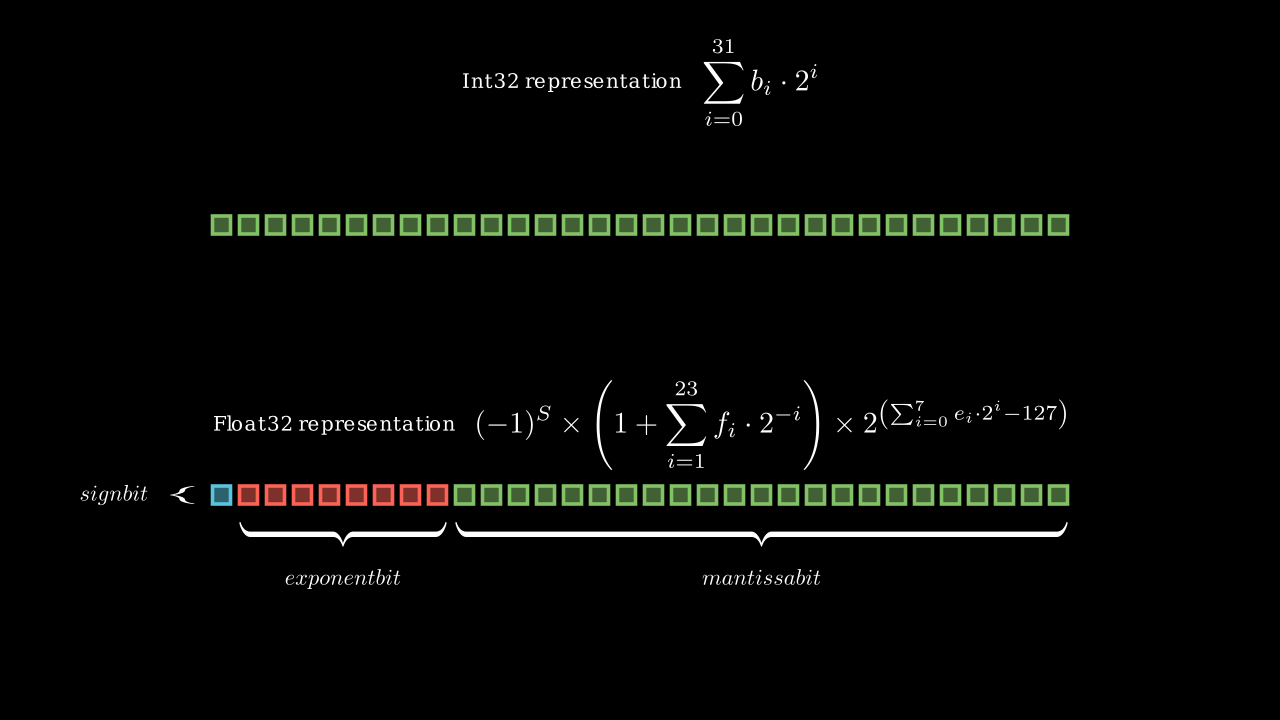
sing base-2 (binary) representation for floating point numbers minimizes rounding errors compared to higher bases. Higher base systems often introduce unused bits, leading to inefficient memory usage. Furthermore, binary representation aligns with how electronic systems naturally process and store data, making it the optimal choice for computational tasks
Real numbers are infinite between any two integers, but representing them on computers with fixed bit widths involves trade-offs. The density of floating point numbers decays exponentially as we move away from zero, meaning that more precision is available near zero and less as values grow larger. Squeezing infinitely many real numbers into a fixed bit width necessitates approximations. As a result, there are more representable numbers between -2 and 2 than in other regions of the number line.
#include <stdio.h>
#include <math.h>
int main() {
float a = (float)pow(2, 24);
for (int i = 1; i < 10; i++) {
printf("%d, %f\n", i, a + i);
}
}
// 2**24 + 1 = 16777216.000000
// 2**24 + 2 = 16777218.000000
// 2**24 + 3 = 16777220.000000
// 2**24 + 4 = 16777220.000000
// 2**24 + 5 = 16777220.000000
// 2**24 + 6 = 16777222.000000
// 2**24 + 7 = 16777224.000000
// 2**24 + 8 = 16777224.000000
// 2**24 + 9 = 16777224.000000
From the above example we observe that as numbers get larger the spacing between consecutive representable numbers increases. The above case at 2^24 floating point format cannot represent every integer precisely beyond this point.
- 2^24 + 1 the floating point precision is insufficient to capture the difference of just 1 due to rounding error
- 2^24 + 2 the floating point precision allows 16777218 to be represented and skips over 16777217.
this phenomenon is called as floating point precision loss at higher magnitudes, more integers are
skipped because the system can’t represent every possible number within the limited floating point precision.
FACT:
javascript uses float64 to represent all numeric data types
History of Floating point numbers#
Initially, computers only supported integer arithmetic, as it was sufficient for early applications. However, as computational needs grew, so did the necessity to represent and manipulate decimal numbers. To address this, programmers began emulating floating-point arithmetic through complex algorithms, which required more operations than simple integer addition or subtraction.
Recognizing the inefficiency of these emulations, chip manufacturers started designing dedicated hardware, such as floating-point registers, to execute floating-point instructions in a single cycle. These registers adhere to the IEEE 754 standard, which defines the floating-point format with 1 sign bit, 23 mantissa bits, and 8 exponent bits. Sticking to this standard is critical for ensuring consistency across platforms, allowing programmers to achieve identical results on different systems—vital for reliable and predictable computation.
Evolution#
With the rising concern of the memory wall chip manufacturers build custom low precision floating point
arithmatic such as float8, float16, bfloat16 and tensor-float32.
Efficiency to high precision calculations#
Floating-point operations, due to the limitations of their representation, come with some inherent drawbacks. One key issue is that they are not strictly commutative—meaning a+b≠b+a in certain cases, particularly in low-precision arithmetic. This non-commutativity increases rounding errors, especially in embarrassingly parallel applications, where threads process operands out of order. While floating-point arithmetic typically works well in serial execution, issues arise when code is parallelized or when the order of operations (like in loops) is changed, leading to slight variations in results.
Because of these precision issues, it is a common practice not to validate floating-point results by checking for exact equality. Instead, computations are often considered correct if the results fall within a specified tolerance range, ensuring that small rounding errors do not invalidate the outcome.